Hbase是什么
hbase是一款数据库,mysql它也是数据库,但是我们称之为传统的关系型数据库。Hbase是适合大数据分析的数据库。我们考虑一下mysql是怎么存的?一条记录一行这种方式适合保存数据和提取数据。但是我们想象大数据情况下,我们要每条记录是没有意义的,我们往往都是找出某一列对所有记录进行分析,比如平均工资,我们不关心某个人的工资,但是我们需要整个列的工资。而hbase就是按列存储的数据库。
HBase的起源
HBase的原型是Google的BigTable论文,受到了该论文思想的启发,目前作为Hadoop的子项目来开发维护,用于支持结构化的数据存储。
官方网站:http://hbase.apache.org
- 2006年Google发表BigTable白皮书
- 2006年开始开发HBase
- 2008年北京成功开奥运会,程序员默默地将HBase弄成了Hadoop的子项目
- 2010年HBase成为Apache顶级项目
- 现在很多公司二次开发出了很多发行版本,你也开始使用了
Hbase的特点
和传统数据库表相比hbase有如下不同:
- 巨大:一个表可以有数十亿行,上百万列,他不像传统数据库为了减少数据的冗余分很多表。
- 面向列:面向列(族)的存储和权限控制,列(族)独立检索;
- 稀疏:对于空(null)的列,并不占用存储空间,表可以设计的非常稀疏;
- 数据多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是时间戳;
- 数据类型单一:Hbase中的数据都是字符串,没有类型。
Hbase中的一些概念
表
Hbase中的表大概长这个样子和mysql表的概念是类似的。表中有行有列

列族
有意思的是表中有列但是多个列上面还有一个概念叫列族。列和列族的关系是一个列族内可以有多个列并且可以动态增减。这时非常奇怪的一个设计我们解释一下。
首先,hbase认为我们一般不会有全列查询就是类似于select * 的操作。这样的话每个列族有独立的存储单元可以提高查询效率。通过将列分成不同的列族hbase可以更少的访问磁盘。所以千万不要把经常查询的两个列放在不同的列族里,这样会导致hbase要访问两块磁盘区域。
rowkey
行键,非常关键类似mysq中的主键唯一标识一行记录。我们知道要想做到高效速度快就离不开索引,hbase就是真的使用rowkey做索引。而且会根据row可以进行排序,保证类似或相同的rowkey都集中在一起,以提高效率。
数据类型
hbase中存储的都是二进制信息,所以没啥数据类型的概念,操作时以字符串格式为基准。
cell
存储数据的单元格。
Timestamp
时间戳 hbase根据时间戳来区别相同rowkey记录。
总述:Hbase中存储数据的最基本的单位是列,一列或多列单元格数据形成一行,并由row key决定。一个表有若干行。每列可能有多个版本。
Hbase的基本工作原理
用户在表格中存储数据,每行都有一个可排序的主键和任意多的列。由于是稀松存储,所以同一张表里面的每行数据都可以有截然不同的列。
列名字的格式是“
但是限定符(qualifier)的值相对于每一行来说都是可以改变的。HBase把同一个列族里面的数据存储在同一个目录底下,并且HBase的写操作是锁行的,每一行来说都是一个原子元素,都可以加锁。
HBase所有数据的更新都有一个时间戳标记,每个更新都是一个新的版本,HBase会保留一定数量的版本,这个值是可以设定的。客户端可以选择获取距离某个时间点最近的版本单元的值,或者一次获取所有版本单元的值。
HBase的环境角色
HMaster功能简述
- 监控RegionServer
- 处理RegionServer故障转移
- 处理元数据的变更
- 处理region的分配或移除
- 在空闲时间进行数据的负载均衡
- 通过Zookeeper发布自己的位置给客户端
RegionServer功能简述
- 负责存储HBase的实际数据
- 处理分配给它的Region
- 刷新缓存到HDFS
- 维护HLog
- 执行压缩
- 负责处理Region分片
组件简述
Write-Ahead logs
HBase的修改记录,当对HBase读写数据的时候,数据不是直接写进磁盘,它会在内存中保留一段时间(时间以及数据量阈值可以设定)。如果机器突然原地爆炸,把数据保存在内存中会引起数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logfile的文件中,然后再写入内存中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
HFile
这是在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。
Store
HFile存储在Store中,一个Store对应HBase表中的一个列族
MemStore
顾名思义,就是内存存储,位于内存中,用来保存当前的数据操作,所以当数据保存在WAL中之后,RegsionServer会在内存中存储键值对。
Region
Hbase表的分片,HBase表会根据RowKey值被切分成不同的region存储在RegionServer中,在一个RegionServer中可以有多个不同的region
Hbase的架构
HBase 一种是作为存储的分布式文件系统,另一种是作为数据处理模型的 MR 框架。因为日常开发人员比较熟练的是结构化的数据进行处理,但是在 HDFS 直接存储的文件往往不具有结构化,所以催生出了 HBase 在 HDFS 上的操作。如果需要查询数据,只需要通过键值便可以成功访问。
架构图示:
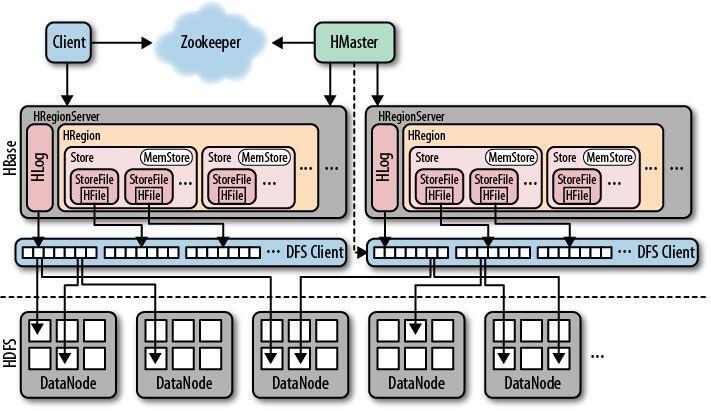
HBase内置有zookeeper,但一般我们会有其他的Zookeeper集群来监管master和regionserver,Zookeeper通过选举,保证任何时候,集群中只有一个活跃的HMaster,HMaster与HRegionServer 启动时会向ZooKeeper注册,存储所有HRegion的寻址入口,实时监控HRegionserver的上线和下线信息。并实时通知给HMaster,存储HBase的schema和table元数据,默认情况下,HBase 管理ZooKeeper 实例,Zookeeper的引入使得HMaster不再是单点故障。一般情况下会启动两个HMaster,非Active的HMaster会定期的和Active HMaster通信以获取其最新状态,从而保证它是实时更新的,因而如果启动了多个HMaster反而增加了Active HMaster的负担。
一个RegionServer可以包含多个HRegion,每个RegionServer维护一个HLog,和多个HFiles以及其对应的MemStore。RegionServer运行于DataNode上,数量可以与DatNode数量一致。
参考架构图: