一、HA说明 HA指高可用,指当当前工作中的机器宕机后,会自动处理这个异常,并将工作无缝地转移到其他备用机器上去,以来保证服务的高可用。
二、集群规划
服务
centeros1
centeros2
centeros3
zookeeper
√
√
√
NameNode
×
√
√
DataNode
√
√
√
ResourceManage
×
×
√
NodeManager
√
√
√
journalnode
√
√
√
zkfc
×
√
√
服务简介:
zookeeper:分布式应用程序协调服务。
Namenode:管理服务。管理元数据,维护目录树,响应请求。
Datanode:hadoop中存储数据。
journalnode:实现namenode数据共享,保持数据的一致性。
ResourceManager:yarn集群中资源的统一管理和分配
Nodemanager:ResourceManager在每台机器上的代理
zkfc:失效检测控制
三、环境准备 3.1、配置hosts,三台机器都需要配置 输入命令:
配置详情:
注:如有红圈内的内容需要加#注释掉,否则会引起:
1 2 java.net.ConnectException: Call From centeros2/192.168.0.176 to centeros2:8020 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
3.2、设置SSH无密码登录,三台机器都需要配置 3.2.1、生成公钥命令:ssh-keygen -t rsa 注:生成公钥过程中一直回车即可,过程中会提示输入密码,直接回车即可,否则使用ssh操作时还会让输入密码。
3.2.2、分发公钥命令:ssh-copy-id centeros1 注:每台机器生成公钥后,将公钥分发给需要操作的机器,同时也需要给自己分发。
3.3、配置NTP服务器 NTP服务器是用来进行时间同步的,来统一集群中各个机器系统时间。
3.3.1、查看是否已安装NTP 1 2 3 4 5 命令:rpm -qa | grep ntp 出现如下信息则说明已经安装了NTP服务否则需要安装NTP ntpdate-4.2.6p5-28.el7.centos.x86_64 ntp-4.2.6p5-28.el7.centos.x86_64
3.3.2、安装NTP 1 在三台机器执行安装NTP命令:yum –y install ntp
3.3.3、配置ntp.conf 选择一台centeros3机器作为NTP服务器 修改ntp配置文件 注释掉以下内容: 1 2 3 4 # server 0.centos.pool.ntp.org# server 1.centos.pool.ntp.org# server 2.centos.pool.ntp.org# server 3.centos.pool.ntp.org iburst
把以下内容注释去掉,如果内容不存在 手动添加 1 2 server 127.127.1.0 # local clock fudge 127.127.1.0 stratum 10
去掉以下内容的# 192.168.30.0 修改自己的网段 192.168.0.0 1 restrict 192.168.30.0 mask 255.255.255.0 nomodify notrap
修改配置文件ntpd: 1 2 3 vi /etc/sysconfig/ntpd 添加一行配置:SYNC_CLOCK=yes
重启ntp服务:service ntpd restart 设置开机启动: chkconfig ntpd on 操作centeros1,centeros2通过contab进行定时同步: 制定定时计划命令:crontab –e 添加内容: 1 0-59/ 10 * * * * /usr/sbin/ntpdate centeros3
测试配置是否有效: 查看系统时间命令: 1 date "+%Y-%m-%d %H:%M:%S"
修改centeros1的系统时间: 1 date -s '2025-01-01 00:00:00'
十分钟后查看centeros1时间是否同步 3.3.4、关闭防火墙 查看状态:
停止防火墙:1 systemctl stop firewalld.service
开机禁止启动:1 systemctl disable firewalld.service
四、安装zookeeper 4.1、配置环境变量 添加如下内容1 2 export ZOOKEEPER_HOME = /home/zookeeper/zookeeper-3.4.13 export PATH = $PATH:$ZOOKEEPER_HOME/bin
4.2、拷贝conf下的zoo_sample.cfg副本,改名为zoo.cfg。 4.3、进入zookeeper目录执行命令: 1 cp conf/zoo_sample.cfg conf/zoo.cfg
4.4、修改zoo.cfg: 4.5、修改zookeeper的数据文件存放的目录: 1 dataDir=/home/zookeeper/data
4.6、添加指定zookeeper集群中各个机器的信息: 1 2 3 server.1=centeros1:2888:3888 server.2=centeros2:2888:3888 server.3=centeros3:2888:3888
4.7、创建节点ID,在配置的 dataDir 路径中添加myid文件 1 echo 1 >> /home/zookeeper/data/myid
4.8、分发到其他机器 1 scp -r / home / zookeeper /zookeeper-3.4.13 centeros1: /home/zookeeper/
4.9、修改每台机器上的myid文件 1 echo 2 > /home/zookeeper/data/myid
注:myid的值对应着zoo.cfg中的配置信息,如server.3=centeros3:2888:3888
4.10、在各个机器上分别启动zookeeper
启动命令:bin/zkServer.sh start
停止命令:bin/zkServer.sh stop
查看zookeeper 启动状态:bin/zkServer.sh status
注:正常状态:一个learder 两个follower
五、配置Hadoop 5.1、配置环境变量 添加hadoop环境变量
1 2 3 4 5 6 7 8 export HADOOP_HOME = /home/hadoop/hadoop-3.1.1 export PATH = $PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin: ``` 启用环境变量 ```shell source /etc/profile
5.2、配置Hadoop JDK路径 修改hadoop-env.sh、mapred-env.sh、yarn-env.sh文件中的JDK路径
1 export JAVA_HOME= /home/java/jdk1.8.0_191
注:如文件中有export JAVA_HOME则去掉注释修改路径,没有则手动添加
5.3、修改slaves文件,指定slave服务器 1 2 3 cd $HADOOP_HOME/etc/hadoop vi slaves
添加内容:
1 2 3 centeros1 centeros2 centeros3
5.4、修改workers文件添加datanode节点 添加内容:
1 2 3 centeros1 centeros2 centeros3
5.5、配置core-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 <configuration > <property > <name > fs.defaultFS</name > <value > hdfs://hadoop</value > <description > HDFS的逻辑服务名,hadoop可以写成任何东西</description > </property > <property > <name > hadoop.tmp.dir</name > <value > /home/hadoop/data/tmp </value > <description > hadoop临时文件存放目录</description > </property > <property > <name > io.file.buffer.size</name > <value > 4096</value > <description > 指定执行文件IO缓存区大小,机器好可以设置大些</description > </property > <property > <name > ha.zookeeper.quorum</name > <value > centeros3:2181,centeros2:2181,centeros1:2181 </value > <description > 指定zookeeper地址</description > </property > </configuration >
5.6、配置hdfs-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 <configuration > <property > <name > dfs.nameservices</name > <value > hadoop</value > <description > HDFS NN的逻辑名称,需要与core-site.xml中的HDFS的逻辑服务名一致,这里使用上面的hadoop</description > </property > <property > <name > dfs.ha.namenodes.hadoop</name > <value > centeros3,centeros2 </value > <description > hadoop逻辑名namenode节点列表,hadoop对应逻辑名</description > </property > <property > <name > dfs.namenode.rpc-address.hadoop.centeros3</name > <value > centeros3:8020</value > <description > hadoop中centeros3的rpc通信地址</description > </property > <property > <name > dfs.namenode.http-address.hadoop.centeros3</name > <value > centeros3:50070</value > <description > hadoop中centeros3的http通信地址</description > </property > <property > <name > dfs.namenode.rpc-address.hadoop.centeros2</name > <value > centeros2:8020</value > <description > hadoop中centeros2的rpc通信地址</description > </property > <property > <name > dfs.namenode.http-address.hadoop. centeros2</name > <value > centeros2:50070</value > <description > hadoop中centeros2的http通信地址</description > </property > <property > <name > dfs.namenode.shared.edits.dir</name > <value > qjournal:// centeros3:8485;centeros2:8485;centeros1:8485/hadoop</value > <description > journalNode 的 URI 地址,活动的namenode会将edit log写入journalNode</description > </property > <property > <name > dfs.journalnode.edits.dir</name > <value > /home/hadoop/data/dfs/jn</value > <description > 用于存放 editlog 和其他状态信息的目录</description > </property > <property > <name > dfs.ha.automatic-failover.enabled</name > <value > true</value > <description > 启动自动failover </description > </property > <property > <name > dfs.client.failover.proxy.provider.hadoop</name > <value > org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value > <description > 实现客户端与 active NameNode 进行交互的 Java类</description > </property > <property > <name > dfs.ha.fencing.methods</name > <value > sshfence</value > <description > 解决HA集群脑裂问题,只允许一个nn写数据</description > </property > <property > <name > dfs.ha.fencing.ssh.private-key-files</name > <value > /root/.ssh/id_rsa</value > <description > the location stored ssh key,指定用户密匙,建议不要用root,用于故障转移,可以不设置</description > </property > <property > <name > dfs.ha.fencing.ssh.connect-timeout</name > <value > 5000</value > <description > ssh连接超时时间,上面秘钥没设置这个也可以不设置</description > </property > <property > <name > dfs.namenode.name.dir</name > <value > /home/hadoop/data/dfs/name</value > <description > namenode数据存放目录</description > </property > <property > <name > dfs.datanode.data.dir</name > <value > /home/hadoop/data/dfs/data</value > <description > datanode数据存放目录</description > </property > <property > <name > dfs.replication</name > <value > 2</value > <description > client参数,node level参数,指定一个文件在hdfs中有几个副本,设置2或3即可,不能多过datanode节点数</description > </property > <property > <name > dfs.webhdfs.enabled</name > <value > true</value > <description > 允许webhdfs,用于数据读取</description > </property > </configuration >
5.7、配置mapred-site.xml 1 2 3 4 5 6 7 <configuration > <property > <name > mapreduce.framework.name</name > <value > yarn</value > <description > mapreduce框架,一般用yarn</description > </property > </configuration >
5.8、配置yarm-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 <configuration > <property > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > <description > nodemanager启动时加载services的方式为mapreduce分配</description > </property > <property > <name > yarn.nodemanager.aux-services.mapreduce_shuffle.class</name > <value > org.apache.hadoop.mapred.ShuffleHandler</value > <description > 实现mapreduce_shuffle的java类</description > </property > <property > <name > yarn.resourcemanager.hostname</name > <value > centeros3</value > <description > resourcemanager节点列表,一个namenode上有即可</description > </property > </configuration >
5.9、分发到其他机器 1 scp -r / home / hadoop /Hadoop-3.1.1 centeros1: /home/ hadoop /
六、启动Hadoop集群 第一次运行hadoop是需要格式化数据,启动会比较麻烦,之后的启动只需要start-all.sh停止stop-all.sh
前提:zookeeper状态正常,jdk状态正常,环境变量设置正常
6.1、启动zookeeper集群,每台机器都执行 1 /home/zookeeper/zookeeper-3.4.13/bin/zkServer.sh start
6.2、主节点centeros3
创建命名空间:bin/hdfs zkfc -formatZK
启动journalnode:sbin/hadoop-daemon.sh start journalnode(三个节点一起启动)
格式化namenode:bin/hdfs namenode -format hadoop
启动namenode:sbin/hadoop-daemon.sh start namenode
启动zfkc:sbin/hadoop-daemon.sh start zkfc
6.3、主节点二centeros2
启动journalnode:sbin/hadoop-daemon.sh start journalnode
从hdfs namenode -bootstrapStandby获取格式化后的元数据:bin/hdfs namenode -bootstrapStandby
启动namenode:sbin/hadoop-daemon.sh start namenode
启动zfkc:sbin/hadoop-daemon.sh start zkfc6.4、从节点一centeros1
启动journalnode1 sbin/hadoop-daemon.sh start journalnode
上面三个节点命令运行完成后重启hadoop集群
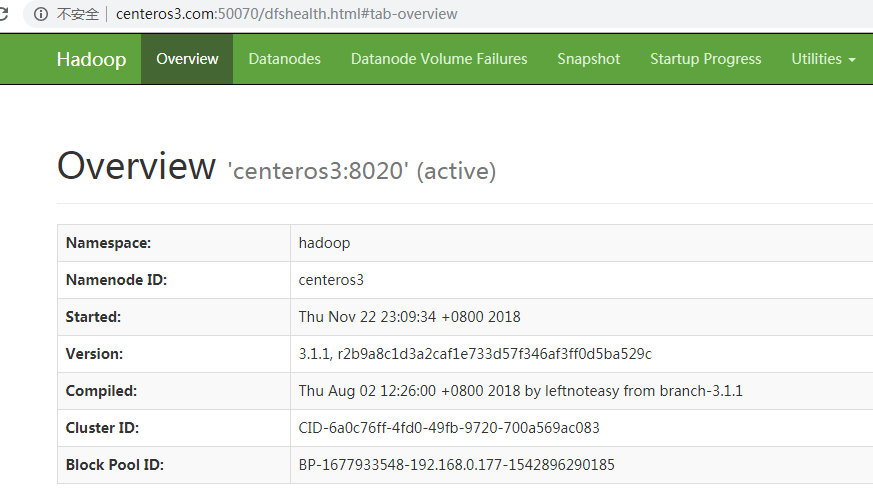
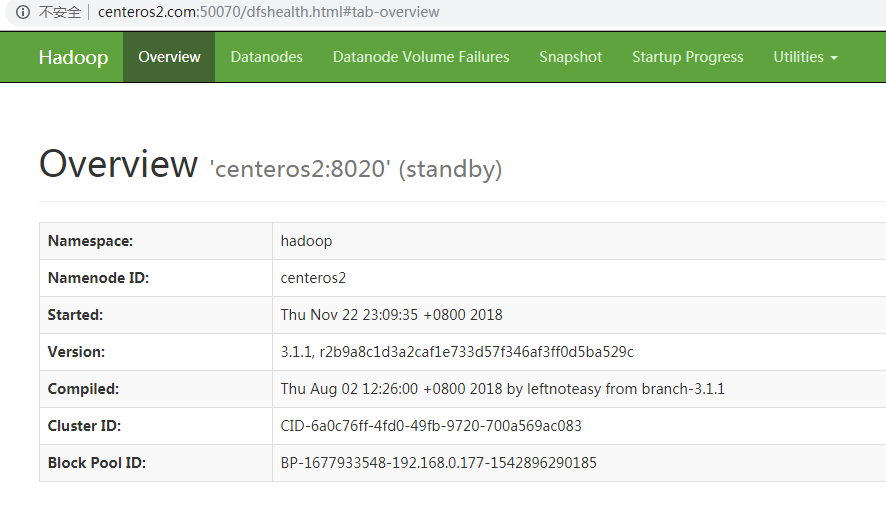
6.5、关闭集群 6.6、启动集群 6.7、成功后页面 6.7.1、centeros3:
6.7.2、centeros2:
6.8、测试HA
在centeros3执行命令:jps
查看namenode进程pid
执行命令:kill -9 pid
打开centeros3 hdfs web已经无法访问,而centeros2已切换为active状态
七、问题解决 错误: 1 2 3 4 5 6 7 8 9 10 11 ERROR: Attempting to operate on hdfs journalnode as root ERROR: but there is no HDFS_JOURNALNODE_USER defined. Aborting operation. Starting ZK Failover Controllers on NN hosts [centeros3 centeros2] ERROR: Attempting to operate on hdfs zkfc as root ERROR: but there is no HDFS_ZKFC_USER defined. Aborting operation. Stopping journal nodes [centeros3 centeros1 centeros2] ERROR: Attempting to operate on hdfs journalnode as root ERROR: but there is no HDFS_JOURNALNODE_USER defined. Aborting operation. Stopping ZK Failover Controllers on NN hosts [centeros3 centeros2] ERROR: Attempting to operate on hdfs zkfc as root ERROR: but there is no HDFS_ZKFC_USER defined. Aborting operation.
解决办法: 是因为缺少用户定义造成的,所以分别编辑stop-yarn.sh、start-yarn.sh加入1 2 YARN_RESOURCEMANAGER_USER=root YARN_NODEMANAGER_USER=root
start-dfs.sh,stop-dfs.sh加入
1 2 3 4 HDFS_NAMENODE_USER=root HDFS_DATANODE_USER=root HDFS_JOURNALNODE_USER=root HDFS_ZKFC_USER=root
stop-all.sh、start-all.sh加入
1 2 3 4 5 6 HDFS_NAMENODE_USER=root HDFS_DATANODE_USER=root HDFS_JOURNALNODE_USER=root HDFS_ZKFC_USER=root YARN_RESOURCEMANAGER_USER=root YARN_NODEMANAGER_USER=root
问题:子节点没有datanode进程。 解决办法:
在sbin下发起./stop-all.sh关闭集群
删除存放hdfs数据块的文件夹(hadoop/data/tmp/),然后重建该文件夹
删除hadoop下的日志文件logs
在bin文件夹下./hadoop namenode -format格式化hadoop
重启hadoop集群